Waste and under-utilization
- Annual compute spend is lost across large job volumes
- Several million CPU-hours can be wasted each year
- Average utilization sits far below requested capacity
The HPC Resource Intelligence Agent helps teams reduce compute waste, improve resource sizing, and surface actionable recommendations before jobs hit the cluster.
Illustrative scientific computing efficiency signals from the workflow optimization accelerator.
Average CPU and memory utilization across millions of jobs
Over-provisioned jobs identified as recovery opportunities
Engineered features used during ingestion from workflow and user history
Illustrative queue delays caused by inefficient allocation patterns
When workloads are routinely over-sized, clusters lose capacity, costs rise, and scheduling performance suffers. The result is wasted compute, limited visibility, and slower execution across shared infrastructure.
This ML-powered layer forecasts resource needs from historical job patterns and turns that prediction into practical recommendations teams can act on immediately.
A clear four-step workflow transforms operational history into smarter allocation decisions.
Capture 35 engineered features from workflow and user history to establish the input context.
Use a multi-output regressor to estimate CPU, memory, and runtime needs before execution.
Return right-sized allocations with confidence and ready-to-use job submission guidance.
Make optimization continuous with self-service dashboard and CLI workflows.
Real interface views show how the Workflow Optimization Engine summarizes cluster health, recommends right-sized resources, and identifies workflows and users with the highest waste.
The landing view summarizes total jobs, users, CPU and memory efficiency, wasted cost, model status, cluster health, and data coverage in one operating view.

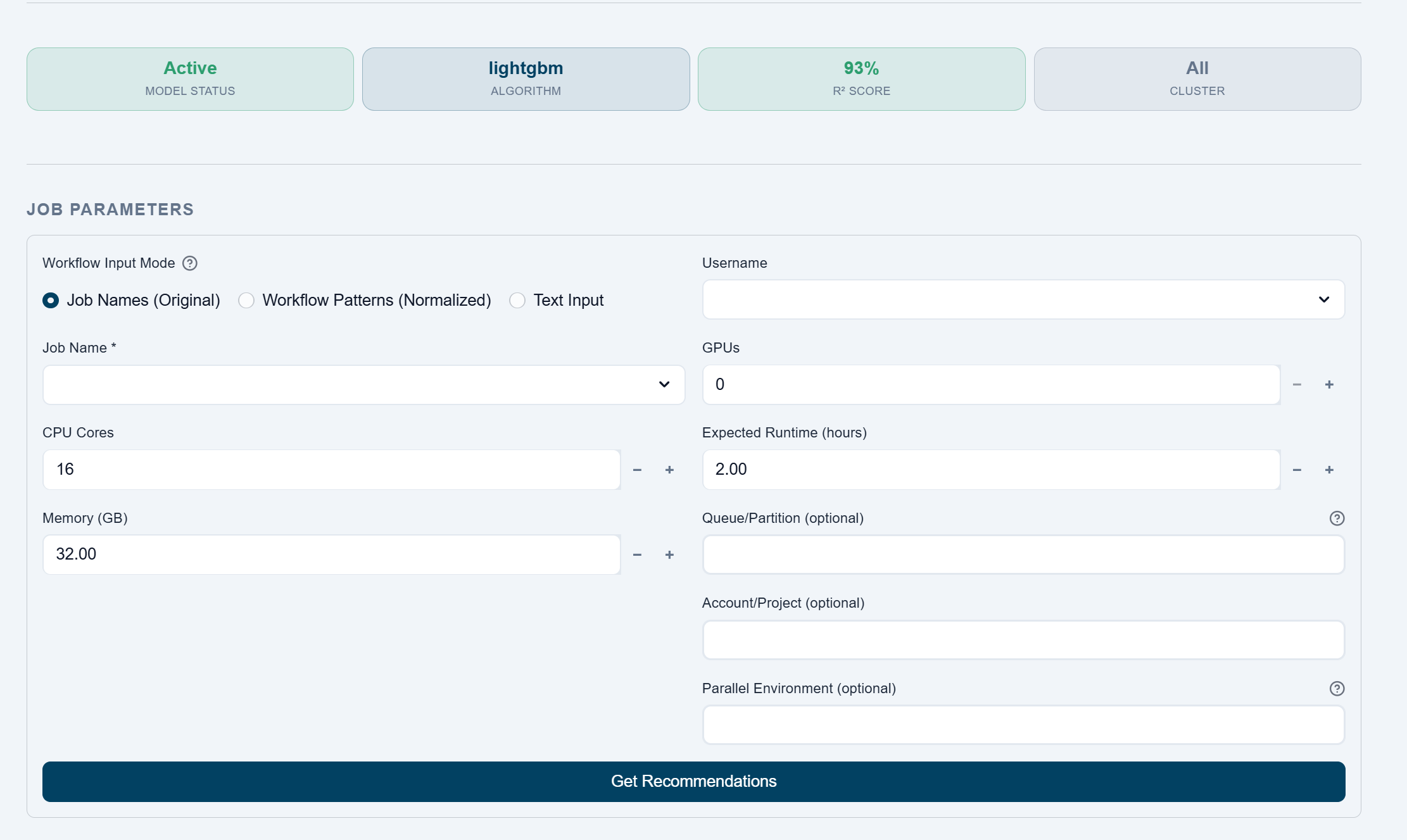
Users enter job names, workflow patterns, CPU, memory, GPU, runtime, queue, project, and environment details to receive model-backed right-sizing guidance.
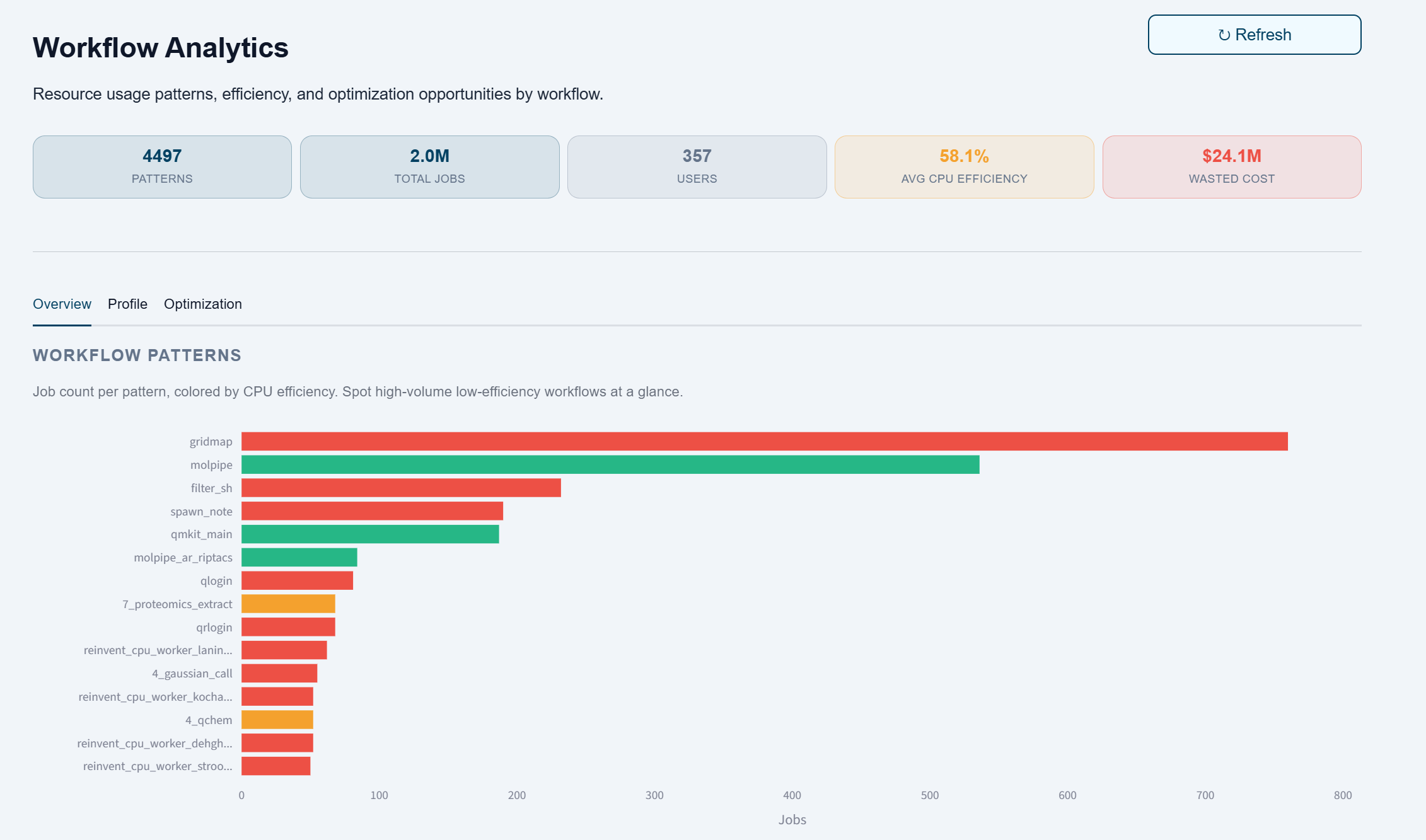
Workflow analytics reveal high-volume, low-efficiency patterns so platform teams can focus optimization where the impact is highest.
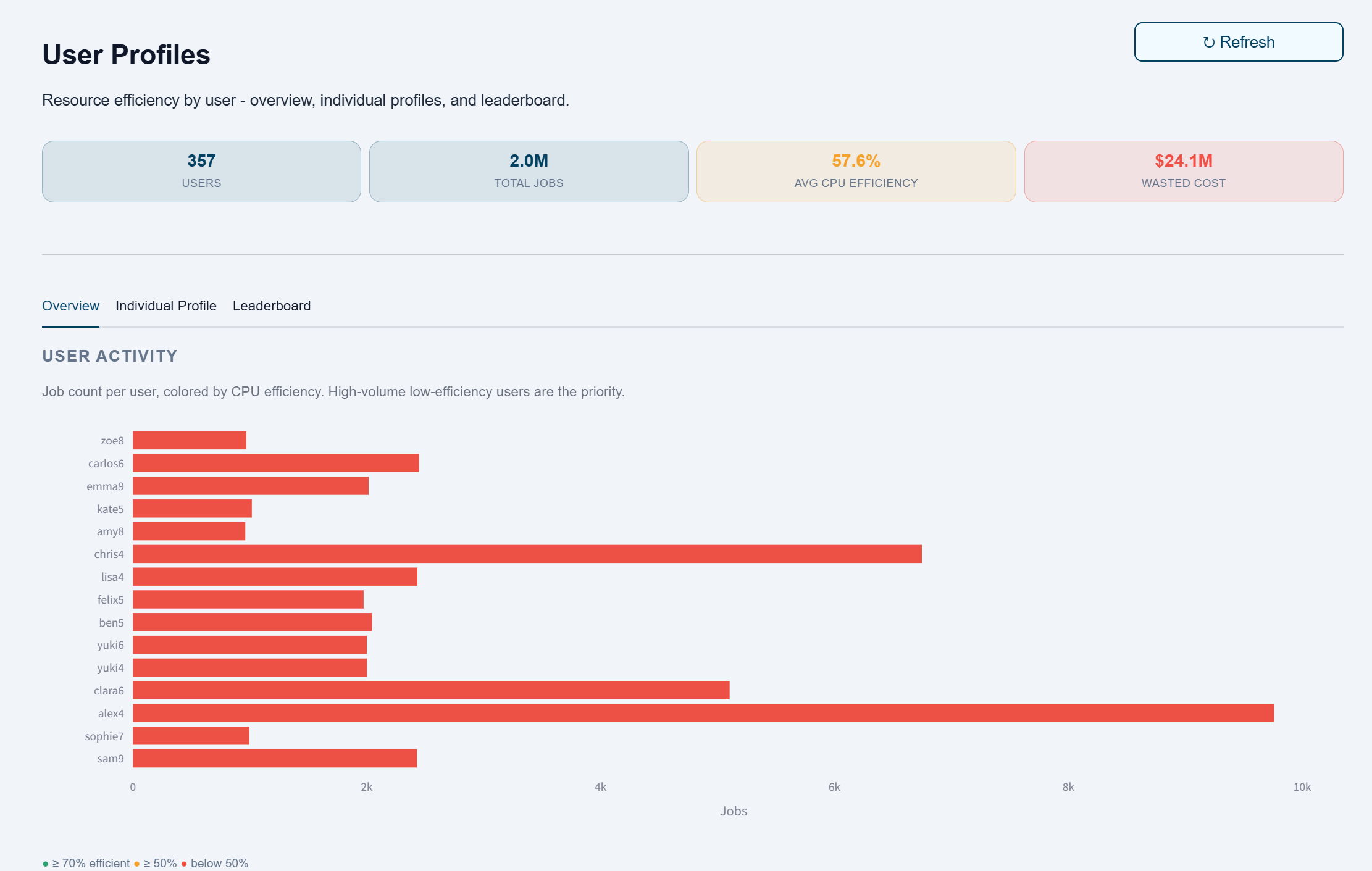
User activity views highlight heavy usage, efficiency variation, and coaching opportunities for targeted HPC optimization.
Optimization is positioned as a cost-reduction strategy and a throughput multiplier for HPC operations.
Recover capacity from jobs that request more compute than they actually consume.
Improve queue behavior and fit more jobs onto the same infrastructure.
Enable self-service retraining and recommendation loops that drive measurable value quickly.
Book a walkthrough to see how Clovertex can apply workflow optimization, right-sizing recommendations, and continuous efficiency insights to your HPC environment.