01
Infrastructure Engineering
HPC enabled cloud services for scientific compute and storage.
Read moreClovertex supports multiomics and bioinformatics programs with infrastructure engineering, pipeline engineering, data analytics and visualization, web app based solutions, professional services, scientific solutions, and metadata management for healthcare and research environments.
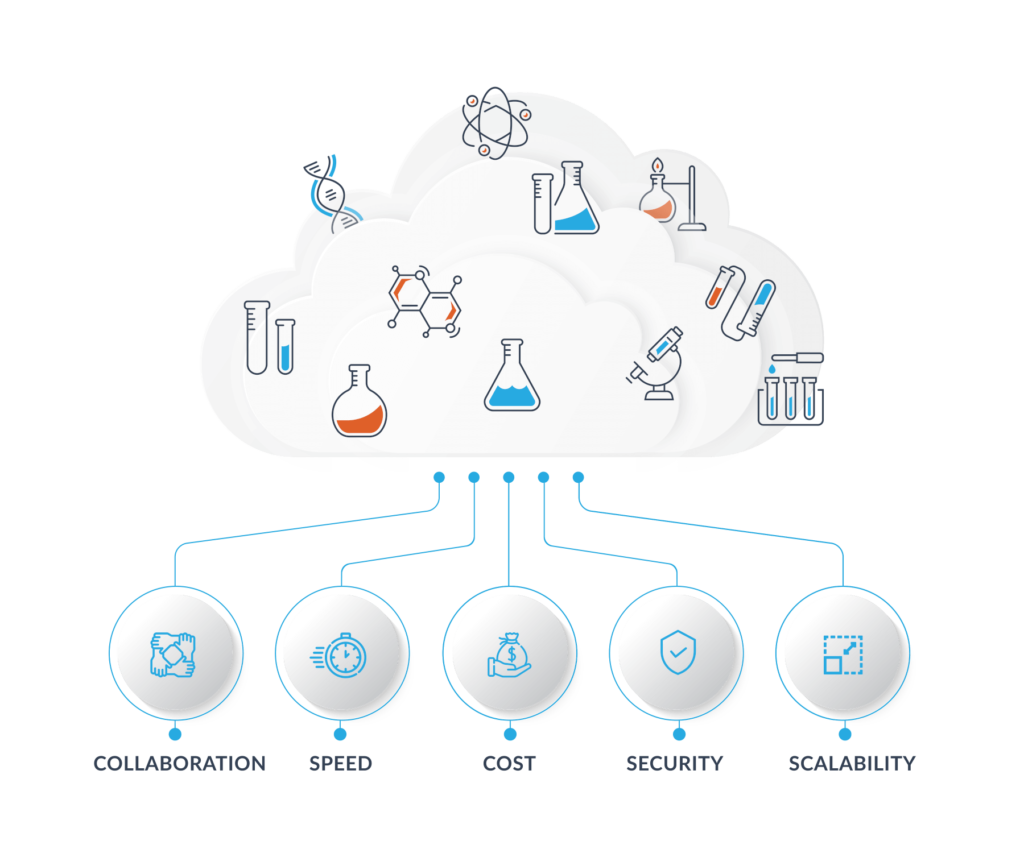
From HPC-enabled cloud services to metadata-rich data lakes, Clovertex aligns engineering, scientific workflows, and analytics in one operating model.
Clovertex organizes its multiomics and bioinformatics capabilities around six solution pillars spanning infrastructure, pipelines, analytics, metadata, collaboration, and ongoing operations.
HPC enabled cloud services for scientific compute and storage.
Read moreDevelopment, scaling, automation, and optimization of workflows.
Read moreAI, ML, and advanced interpretation for multi-omics programs.
Read moreUser-facing applications for pipeline access and result interpretation.
Read moreHypercare, support, and scientific solution delivery for research teams.
Read moreData lake and database management for bioinformatics in the cloud.
Read moreClovertex experience spans DNA and RNA sequencing, microarray, single-cell, epigenetics, metagenomics, drug biomarker workflows, and related proteomics and metabolomics practices.
“The Clovertex team we worked with [to scale genomics workflows on HealthOmics] demonstrated a high level of technical knowledge, relevant experience and professionalism. They were all very open, honest and pragmatic, which I really value and were key to enabling productive collaboration. Overall, they were a pleasure to work with and I would work with them again if the opportunity came up.”
Director, IT · Large Sequencing Technology Provider
Scientific cloud computing and HPC services help solve data storage, workflow organization, environment configuration, and batch processing challenges. A strong HPC foundation enables parallel computing instead of traditional sequential execution, reducing time and resource utilization while increasing the scale of innovation.
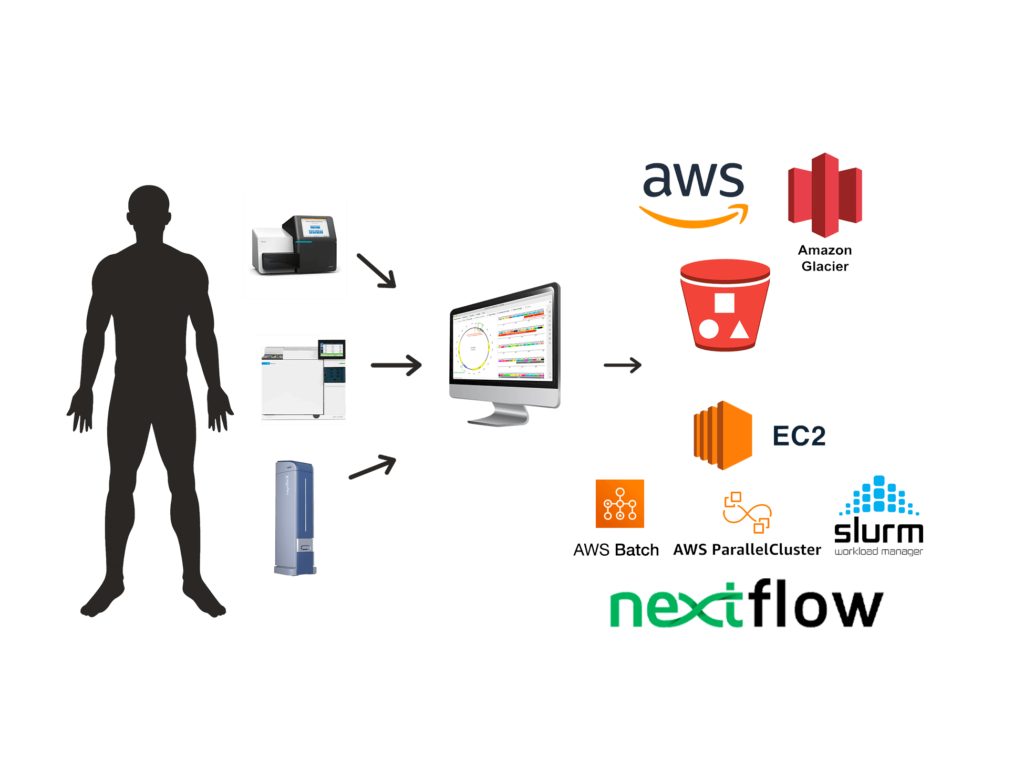
Clovertex provides expertise in building high-performance computing architecture for deploying and processing a variety of pipelines and large-scale multi-omics data, across both cloud and on-premises environments, with guidance on infrastructure selection and migration support.
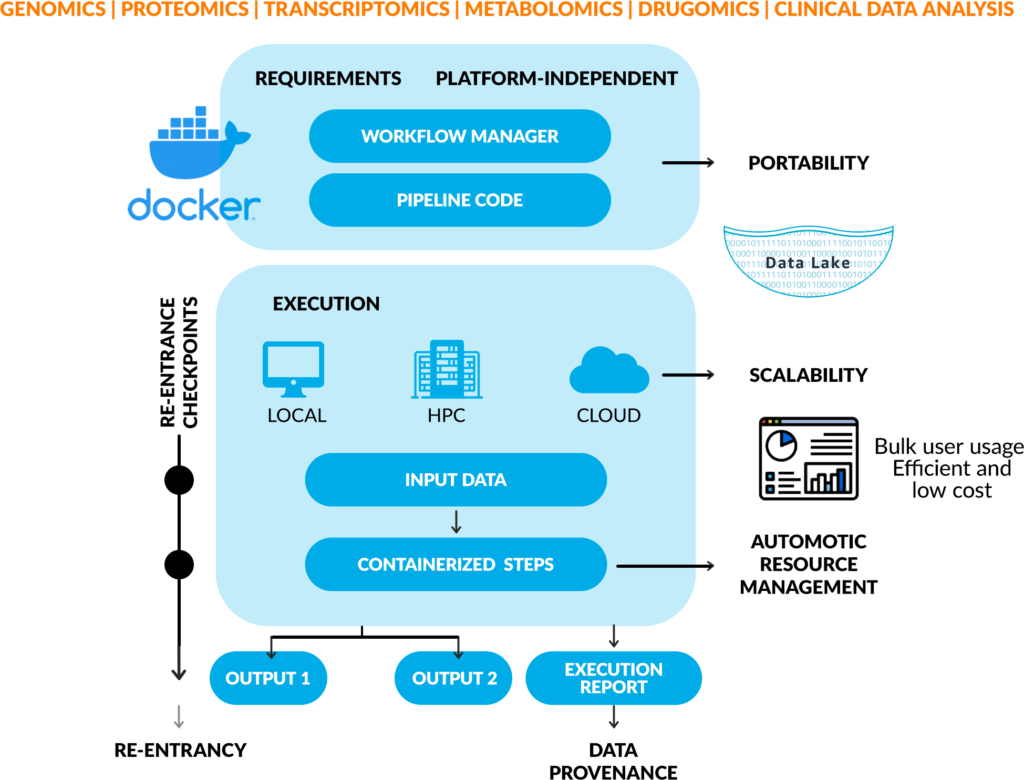
Pipeline engineering covers data ingestion, pre-processing, analysis, storage, and report generation for consumer genomics, clinical genomics, hospitals, and pharmaceutical organizations. Next-generation sequencing and multi-omics studies can generate petabyte-scale data that overwhelm shell-script based workflows.
It also highlights workflow managers such as Nextflow and Cromwell, containerized approaches, and integration with AWS Batch, ECS, and Parallel Clusters to improve deployment, observability, automation, efficiency, and scalability.
Clovertex states experience modularizing workflows for bulk data and multi-user requirements, including DNA/RNA sequencing, microarray, single-cell, epigenetics, metagenomics, and drug biomarker pipelines.
Data analytics is essential for drug discovery and precision medicine, especially where omics data volumes make interpretation difficult on traditional timelines.
The page describes analytics and visualization as a path from raw data to understandable conclusions, especially for large-scale multi-omics experiments.
Clovertex applies artificial intelligence, machine learning, data science, and NLP to disease prediction, mechanism-of-action work, gene regulation, molecular profiling, and repository annotation workflows.
Clovertex states that it helps customers build decision-making skills, interpret predictions, and support non-technical users adopting data-driven approaches for multi-omics studies.

Web applications give technical and non-technical users a platform to implement pipelines and interpret results across multiple experiments and case studies. These interfaces can be deployed in client environments for multi-user access and bulk job management.
Shiny and Django-based applications can serve as front-end layers for algorithms running in HPC or AWS environments, with integration into broader data-lake architectures for analysis and visualization.
It also says Clovertex develops applications using R Shiny, Python Django, and full-stack HTML / Angular patterns for visualization and interpretation of experimental, annotation, clinical, population, disease-specific, and drug repurposing data.
Clovertex partners with teams on ongoing support, system maintenance, data migration, application upgrades, and specialized scientific computing operations that typical enterprise IT teams may not be equipped to manage alone.
Bulk data management across raw, analyzed, pre-processed, and unstructured healthcare data is a major multiomics challenge. Cloud-based data lakes and databases help organize and store data, accelerate access, and make results reusable across experiments and domains.
Clovertex states that it provides cloud data storage and management solutions for healthcare and multi-omics, including customer-owned data lakes with interactive APIs and dashboard UIs, plus migration, scaling, and deployment support.
This operating flow connects infrastructure readiness, pipeline engineering, metadata strategy, analytics, and long-term support.
Clovertex work connects healthcare, multi-omics analytics, genomics pipelines, drug discovery, precision medicine, and scientist-friendly deployment and interpretation models.
Infrastructure engineering is framed around solving storage, workflow, environment, and batch-processing challenges with scientific cloud computing and HPC.
Pipeline engineering is positioned around workflow managers, containers, automation, performance reporting, and scalable cloud integration for genomics and multi-omics workloads.
Analytics, visualization, AI, ML, and NLP are presented as important enablers for transforming massive raw datasets into useful findings for drug discovery and precision medicine.
Bring your infrastructure question, pipeline challenge, analytics objective, or metadata strategy. Clovertex can help define the right implementation path.