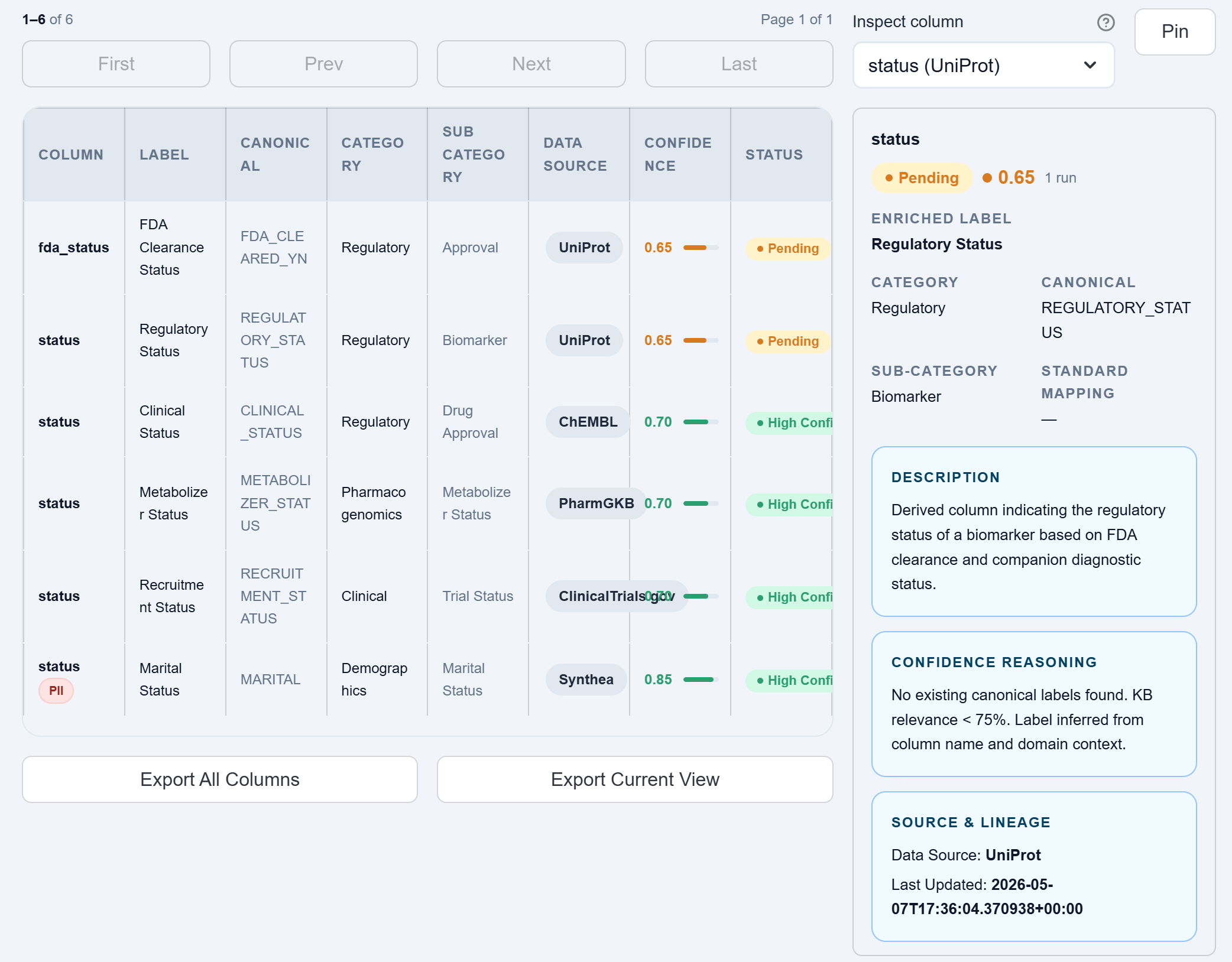
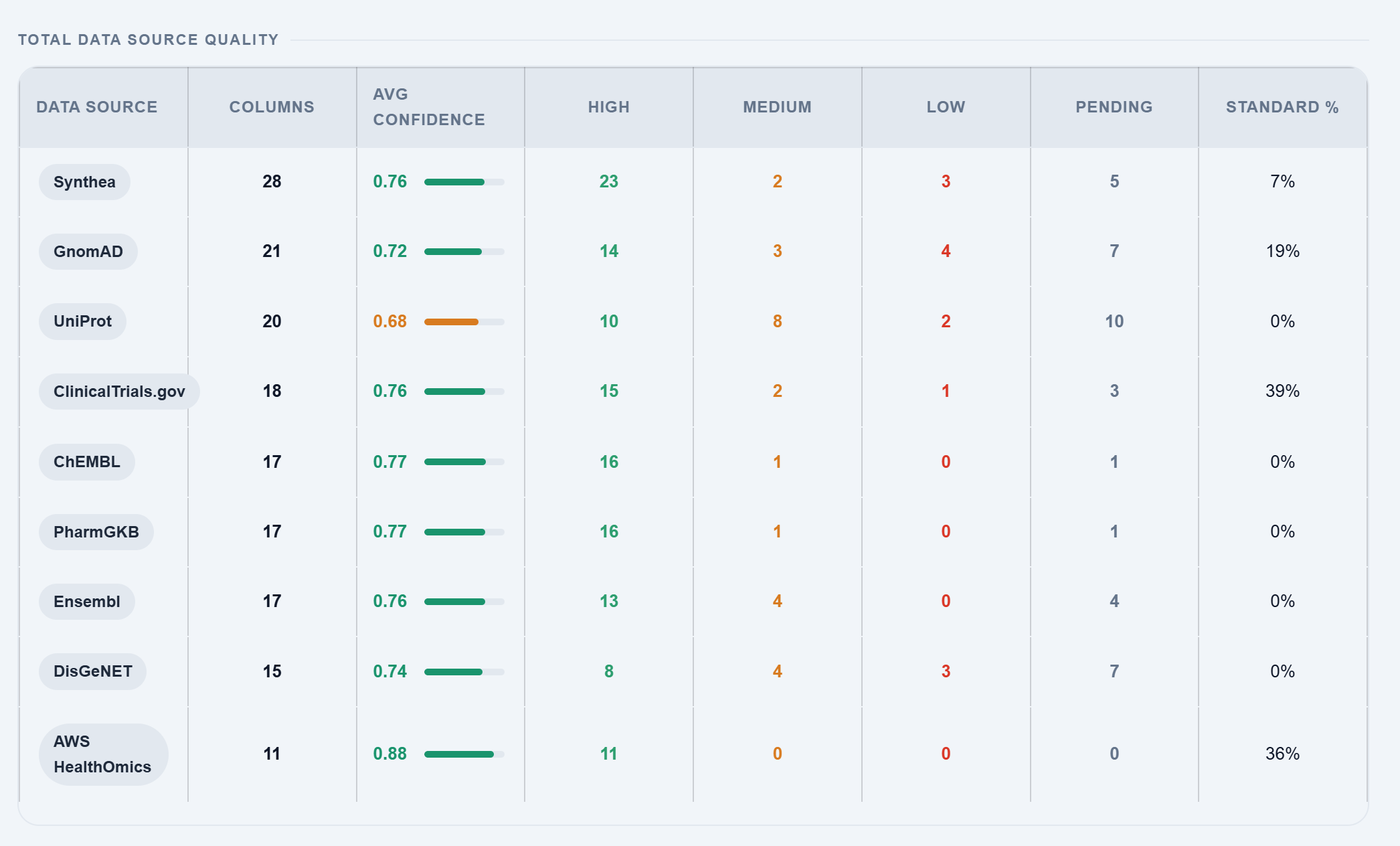
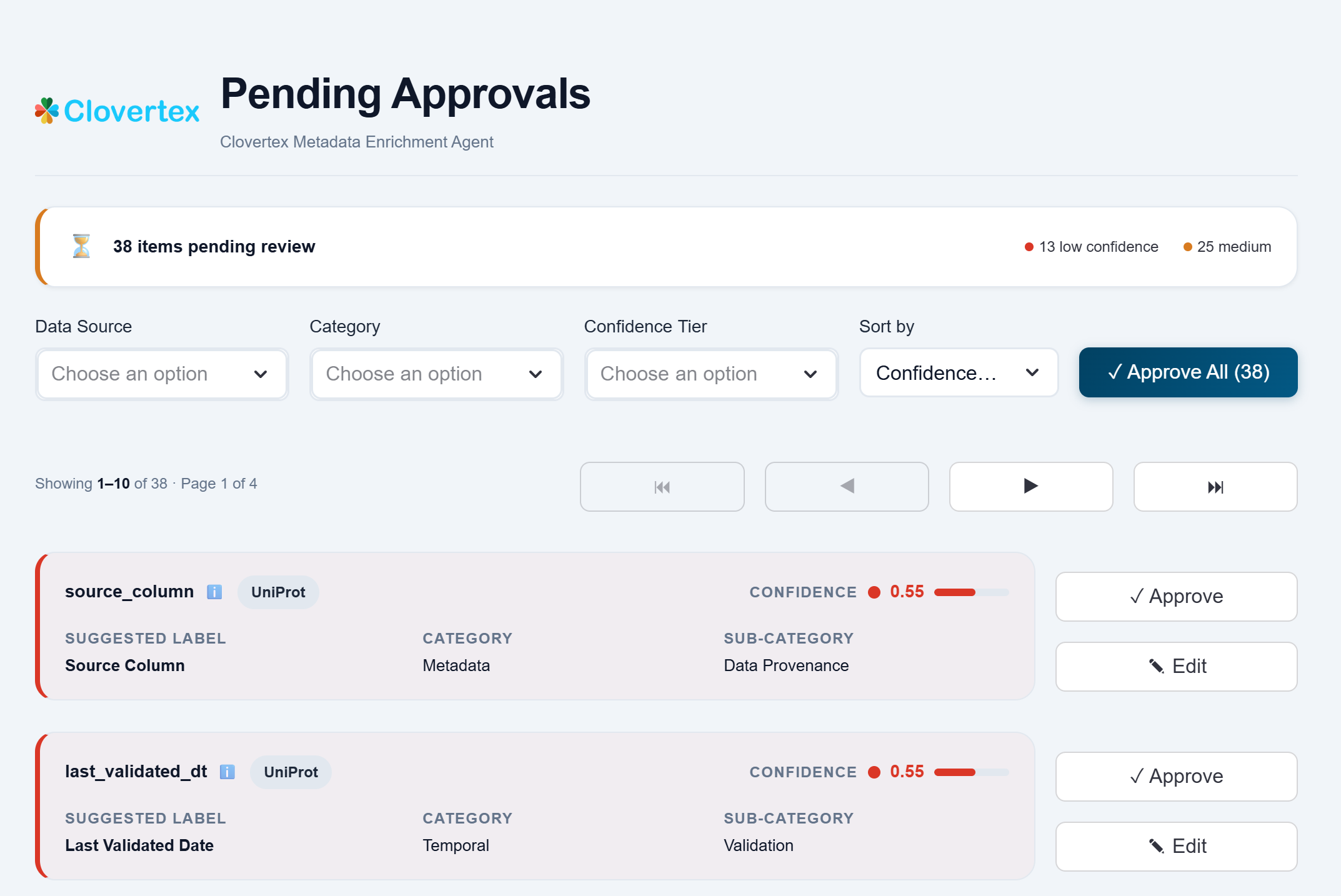
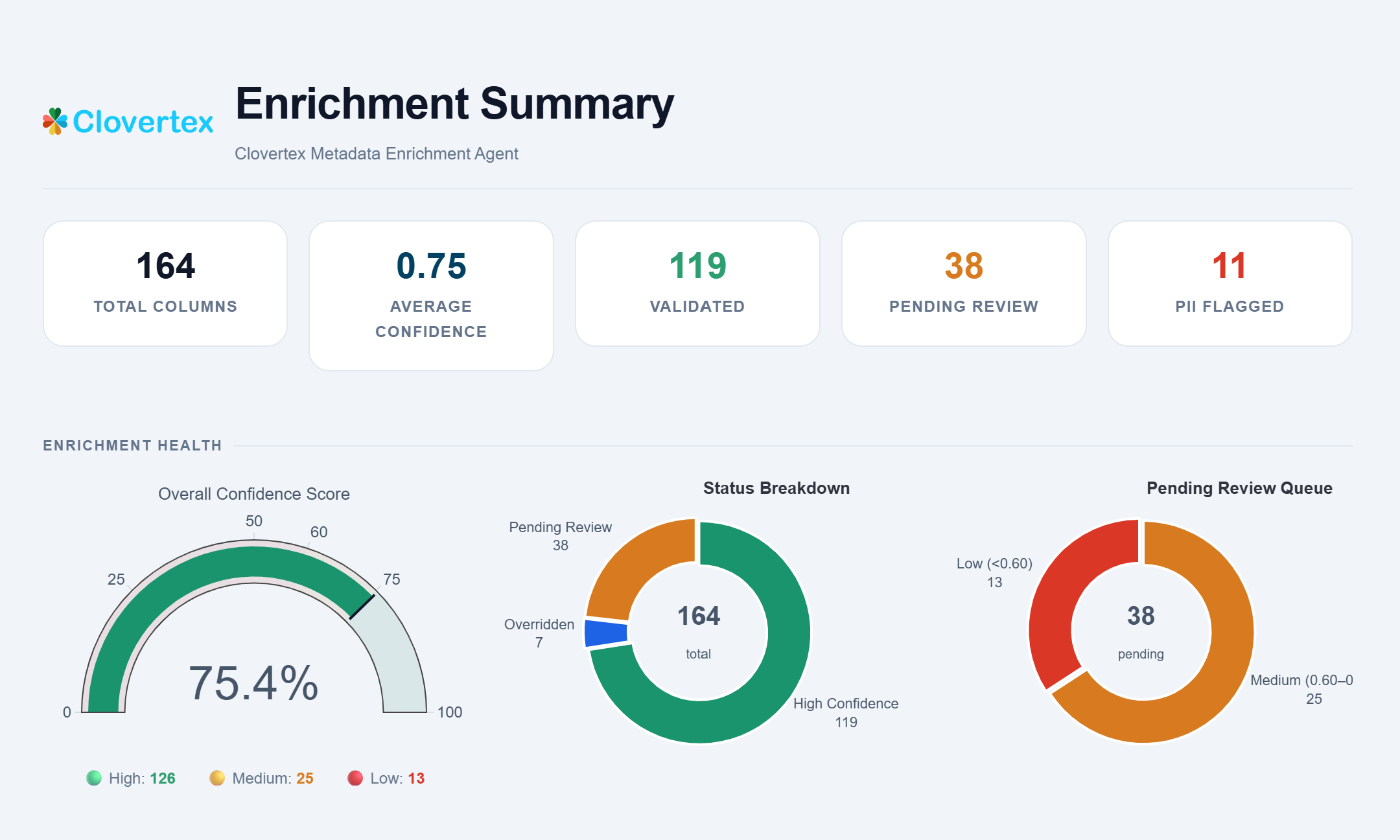
Why generic column names break pharma analytics
- The same raw column name can appear in regulatory, clinical, pharmacogenomics, and demographic sources
- Teams lose time deciding whether “status” means FDA clearance, trial recruitment, metabolizer phenotype, or something else
- Without a consistent semantic layer, downstream analytics inherit inconsistent business definitions